En este artículo vamos a ver qué es un APM, por qué son imprescindibles para que un software funcione de forma fluida, exploraremos un ejemplo de APM gratuito y de código abierto, y analizaremos los principales problemas de rendimiento del software y cómo solucionarlos.
¿Qué es un APM y por qué es imprescindible?
Un APM (Application Performance Monitoring) no es otra cosa que un software que te permite monitorizar y analizar el rendimiento de una aplicación. Ayuda a identificar cuellos de botella y tiempos de respuesta elevados. Sus beneficios son múltiples:
- Diagnosticar problemas antes de que le sucedan a usuarios finales, gracias a que se pueden reproducir de forma local.
- Visualizar el comportamiento de la aplicación con métricas y gráficos detallados.
- Reducir el tiempo de resolución de incidencias.
- Mejorar continuamente la calidad del software.
En resumen, un APM proporciona visibilidad profunda sobre lo que realmente está ocurriendo en tu sistema, lo que a día de hoy, no es que sea importante, es imprescindible.
Glowroot: un APM ligero y potente
Glowroot es una herramienta APM de código abierto para aplicaciones Java. Su principal ventaja es que es ligero, fácil de configurar y con una interfaz muy clara. A pesar de su simplicidad, ofrece funcionalidades similares a herramientas comerciales.
¿Cómo poner en marcha Glowroot?
1. Descarga Glowroot desde https://glowroot.org.
2. Descomprime el archivo en tu ordenador.
3. Añade el agente a tu JVM al iniciar la aplicación (esto se hace al arrancar la aplicación desde tu IDE, normalmente en el apartado donde te pone VM params)
-javaagent:/ruta/a/glowroot.jarTe dejo como quedaría la configuración tal cual en mi ordenador.
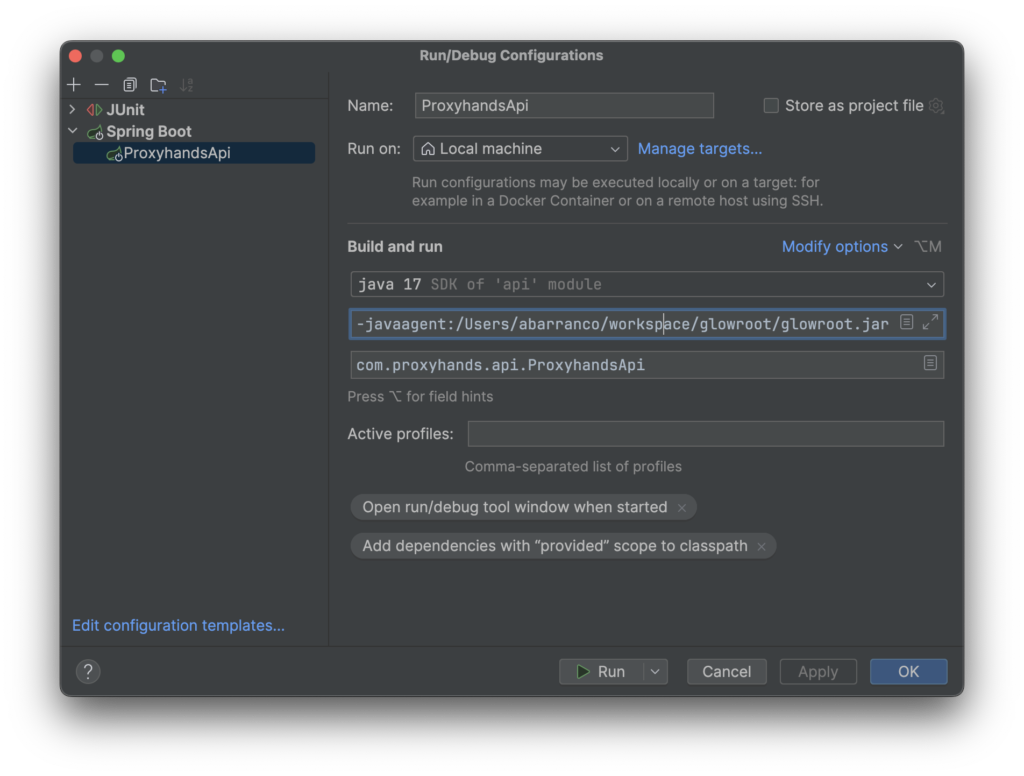
Por defecto Glowroot arranca en el puerto 4000, y de hecho en los logs al arrancar la aplicación te lo confirma. Si todo ha ido bien deberías ver algo como lo siguiente al acceder a http://localhost:4000
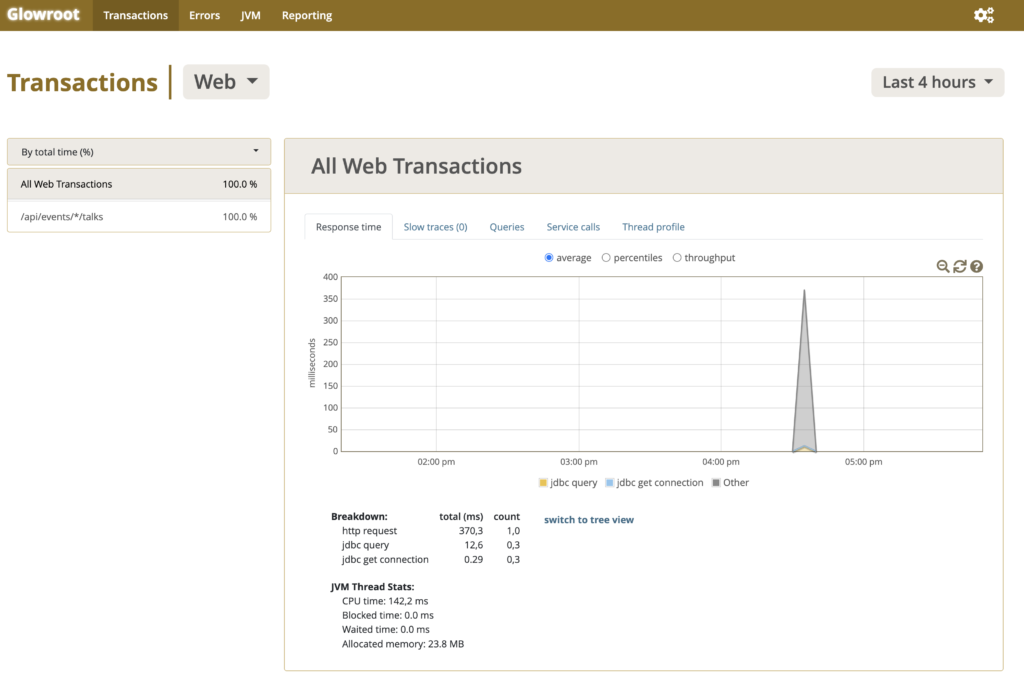
Esta es la vista principal de Glowroot, donde ves los tiempos de respuesta.
Antes de empezar a hacer nada te recomiendo ajustar un poco la configuración. Esto lo podemos hacer si hacemos clic en la rueda de la esquina superior derecha.
En esta vista a mi me gusta configurar el tiempo mínimo para considerar una respuesta lenta en 100 milisegundos. Por defecto está a 1 segundo, y para mi eso es demasiado.

No te olvides de guardar los cambios antes de salir.
Ahora cada vez que tu aplicación tarde más de 100 milisegundos en realizar una operación vamos a poder verla y detectarla. Para ello tenemos que volver a la vista anterior, y hacer alguna operación en la aplicación. Yo como estoy usando ProxyHands, he efectuado varias llamadas al API, y hay 2 que han tardado más de 100 milisegundos.
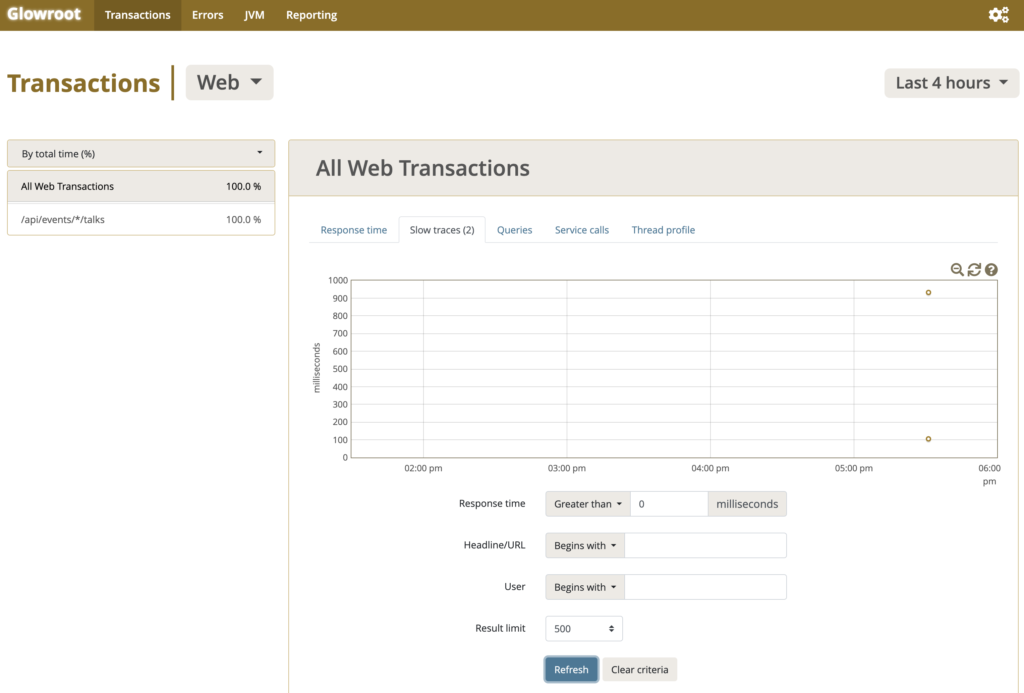
Puedes ver que en Slow traces, ya me dice que tengo 2 lentas. Y además en el gráfico salen dos puntos amarillos que identifican a exactamente las llamadas que han ido lentas. Una ventaja que tiene glowroot frente a otros APMs como Dynatrace, es que Glowroot no samplea llamadas y coge solo algunas. Glowroot se queda con absolutamente todas las llamadas que suceden en tu sistema.
Vamos a hacer click en alguna de ellas a ver qué podemos ver.

Aquí se ven un montón de cosas:
- La URL que identifica la petición.
- La duración de la misma, en este caso 932 milisegundos.
- El verbo de la petición, en este caso es un GET.
- El desglose de donde se van los tiempos. Particularmente aquí vemos que la query, que usa jdbc ha tardado solo 3,1 milisegundos, y que conseguir una conexión del pool de conexiones nos ha llevado menos de 1 milisegundo. Esto descarta que tengamos un problema de índices, y que nuestras queries vayan lentas y segundo, descarta que tengamos mal configurado el pool de conexiones de base de datos, pues obtener una nueva conexión no le ha costado prácticamente nada.
- NOTA: Obviamente si estamos haciendo peticiones de forma manual, es difícil que el pool tarde en darnos una conexión, lo suyo sería introducir una carga al sistema similar a la que tengamos en producción, pero eso da para otro artículo aparte.
- Podemos ver que «Allocated memory» en el Main Thread ha sido de 70.9 MB. Esto es muy importante. Si de forma consistente estas peticiones están trayendo a memoria muchísimos objetos, significará que estamos perdiendo muchísimo tiempo en limpiar esos objetos después de la memoria, en Java veríamos mucho tiempo usado en garbage collectors. Mantener este número en valores razonables es muy aconsejable.
- Y si hacemos click en Query stats vemos todas las queries o consultas a base de datos que ha lanzado esta operación, con el tiempo total, la cantidad de veces que se han ejecutado, y la cantidad de objetos que se han traído a memoria. Esta información es MUY importante, ya que suele ser uno de los principales focos de lentitud en nuestras aplicaciones.
- Por último vemos que podemos aventurarnos en los gráficos de calor de esta petición para ver exactamente donde se van los tiempos. Vamos a abrirlo y lo analizamos.
Analizando los gráficos de calor
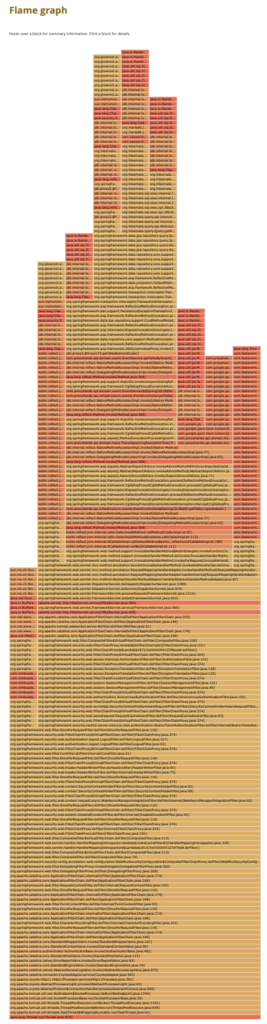
He tenido que hacer muchísimo zoom para que se vea entero. Los gráficos de calor, tienen este aspecto, como si fuera una llama. Se leen de abajo hacía arriba. Nuestra petición empieza en la base, en donde veremos lo siguiente.

Y si pasamos el ratón por cualquiera de las líneas siempre vamos a tener la misma información, vamos a analizarla:
- Lo primero que vemos es la línea exacta de código que se invoca. En este caso tenemos en el paquete java.lang, la clase Thread.java, que tiene un método que se llama run, y este método está definido exactamente en la línea 833 de esa clase.
- Ya en el letrero de la derecha tenemos que esta parte de nuestro código se lleva en ejecutar el 100% de nuestra petición (tiene sentido, porque es la base del gráfico, es decir, contiene el 100% del tiempo de la petición).
Vamos a ver algo más interesante si vamos más para arriba en el gráfico. Podemos ver cosas como esta.

Si te fijas el popup negro nos dice que tenemos la clase TraceAspect, que está en el paquete com.proxyhands.api.domain.trace y que dentro de esa clase tenemos un método en la línea 55 que se llama logExecutionTime, que en este caso esta tardando un 22% del tiempo de la petición.
Si sigo la llama un poco más para arriba dentro de esa columna puedo ver lo siguiente:

Esto me está queriendo decir que todo el tiempo de logging de esta operación se la lleva la librería de Google que usamos en ProxyHands para escribir las trazas, que se llama Gson.
Ahora que tenemos esta información podemos pensar que esto es demasiado tiempo, y proponer alternativas. Podríamos hacer lo siguiente:
- Plantearnos cambiar a otra librería, o incluso formato de traza. Seguramente Json no sea el formato más conveniente para guardar las trazas.
- También podríamos no tener al usuario esperando a que el sistema escriba los logs. Es decir, podríamos hacer la operación asíncrona, y devolver la respuesta en cuanto estuviera disponible al usuario, y ya una vez respondido al usuario escribir la respuesta en los logs.
Esto ha sido solamente un ejemplo, hay muchos problemas de rendimiento y cada uno conlleva ponerse a pensar que se puede hacer en ese caso en concreto. Glowroot es la herramienta que te va a iluminar exactamente cuales son los problemas, y tú como desarrollador tendrás que plantear la mejor alternativa.
Una vez que tengas la mejor alternativa, simplemente la implementas y vuelves a ejecutar la petición. ¿Ha mejorado el rendimiento? ¿Ha empeorado?. Y así es como se itera hasta que se da con una solución que es rápida.
Conclusión: No vale con que algo funcione, tiene que funcionar rápido
No solo es suficiente con usar TDD, patrones y principios de diseño, antes de dar una nueva funcionalidad por finalizada hay que probarla, y eso incluye analizar su rendimiento.
No podemos tener a nuestros usuarios esperando a que les llegue una respuesta. Por lo general, algo que tarda más de 1.5 segundos para el usuario, es sinónimo de que no funciona. A partir de cierto tiempo el usuario se aburre de esperar y cierra la app, o la pestaña del navegador, y eso son menos ventas.
Para terminar diremos que es importante que estas pruebas se realicen con un volumen de datos y peticiones igual o parecido al que tenemos en los entornos productivos que usan los usuarios finales. No tiene sentido probar que funciona la funcionalidad de «dime cuanto dinero tengo en la cuenta», si en nuestra base de datos tenemos 10 cuentas. Tendremos que tener si somos un banco grande, millones de cuentas en la base de datos.
De la misma manera, no vale llamar a «dime mi saldo de cuenta» una vez. Si en picos tenemos en el banco 10.000 usuarios a la vez solicitando esa funcionalidad, deberemos simular ese tráfico para que afloren los problemas.
Sobre el autor:

Alberto Barranco es el fundador y CEO de Osohub. Lleva desarrollando desde el 2010.
En Osohub creamos software de calidad valiéndonos de nuestra experiencia, el aprendizaje continuo y la Inteligencia Artificial.
Desarrollamos software a medida para grandes compañías nacionales e internacionales.